算法小站
首页
wiki
新鲜事
文章搜索
网站导航
回忆录
首页
wiki
新鲜事
文章搜索
网站导航
回忆录
登录
注册
算法基础
搜索
数据结构
字符串
数学
图论
动态规划
计算几何
杂项
wiki 主题
算法基础
二维偏序
高维前缀和
树上差分
中位数定理
搜索
数据结构
线段树
线段树单点修改
线段树区间修改
动态开点线段树
线段树的合并(一)
可持久化线段树
树链剖分
平衡树
FHQ-Treap
珂朵莉树
分块
位分块
根号分治
虚树
字符串
回文串
回文树
数学
组合计数
二项式定理
生成函数(一)
FFT
多项式与形式幂级数
同余与模
同余与模的应用
同余与模的概念
特殊的数
斯特林数
斯特林数相关的恒等式
斯特林数的综合应用
FFT的应用
整除分块
图论
图的连通性
有向图的强连通分量
无向图的割点割边和双连通分量
流和匹配
最大流
最大流的一些应用
最小割
费用流
带上下界的网络流
二分图匹配
二分图最大权匹配
图论杂项
最大团搜索算法
树上问题
kruskal重构树
kruskal重构树的一些问题
最短路
差分约束
动态规划
背包模型
dp优化
凸壳优化
单调队列优化
计算几何
凸包(一)
杂项
启发式合并
高精度
一些经典问题
约瑟夫环
曼哈顿距离
多重集合的排列组合
蔡勒公式
排列与置换
Catalan数与格路径
主题名称
是否为父主题
是否为其添加wiki文章
取 消
确 定
选择主题
修改主题名称
修改父主题
修改wiki文章
取 消
删 除
修 改
算法基础
搜索
数据结构
字符串
数学
图论
动态规划
计算几何
杂项
图论
图的连通性
有向图的强连通分量
无向图的割点割边和双连通分量
流和匹配
最大流
最大流的一些应用
最小割
费用流
带上下界的网络流
二分图匹配
二分图最大权匹配
图论杂项
最大团搜索算法
树上问题
kruskal重构树
kruskal重构树的一些问题
最短路
差分约束
[[ item.c ]]
0
0
二分图最大权匹配
## 二分图带权匹配 考虑处理的图是完全图$$K\_{n, n}$$,如果不满足,可以插入缺少的边,并让其权值为`0` 我们处理的各个边都是非负权值的,所以有某个权值最大的匹配是完美匹配,考虑最大权匹配及其对偶问题 ### 加权二分匹配及其对偶 **问题模型** 有$$n$$个农场生产玉米,$$n$$个加工厂,农产$$i$$生产的玉米,给加工厂$$j$$,产生利润$$w(i, j)$$ 现在需要找到一个匹配,使得总利润最大 同时,政府希望少生产点玉米,如果农业公司不选择农场$$i$$,政府补贴$$u_i$$,如果不使用加工厂$$j$$,政府补贴$$v_j$$ 政府支付的补贴,必须对所有$$i, j, \quad u_i + v_j \geqslant w(i, j)$$成立,同时希望有一个方案,使得$$\sum u_i + \sum v_j$$最小 **定义** **最大权匹配** 一个$$n \times n$$矩阵的**截断**,每行每列各取一个元素得到的$$n$$个位置,找出和最大的一个截断,这就是**最大权匹配问题** 将非负权值$$w(i, j)$$分配给$$K\_{n, n}$$的边$$(x_i, y_j)$$,找出完美匹配$$M$$使得$$w(M)$$最大 **最小权覆盖** 给定所有边的权值,对标记$$\\{u_1, u_2, \cdots, u_n\\}, \\{v_1, v_2, \cdots, v_n\\}$$适当选择 使得$$u_i + v_j \geqslant w(i, j)$$对任意$$i, j$$均成立,覆盖$$(u, v)$$的代价$$c(u, v) = \sum u_i + \sum v_j$$ 最小权覆盖,使得最小的一个覆盖 **最小权匹配** 很简单,选一个很大的$$M$$,然后权值调整成$$M-w(i, j)$$,求最大权匹配 ### 对偶性 对于加权二分图$$G$$的一个完美匹配$$M$$和加权覆盖$$c(u, v)$$,有$$c(u, v) \geqslant w(M)$$ 并且$$c(u, v) = w(M)$$当且仅当$$M$$是满足$$u_i + v_j = w(i, j)$$的边$$(x_i, y_i)$$组成的 简单来说,最大权匹配 = 最小权覆盖 > 证明 > 必要性,在$$M$$的每一条边上,对约束$$u_i + v_j \geqslant w(i, j)$$求和,就有$$c(u, v) \geqslant w(M)$$ 充分性,$$c(u, v) \geqslant w(M)$$对任意匹配和覆盖都成立,$$c(u, v) = w(M)$$就表明最优了 ## 匈牙利算法 **相等子图** 是$$G$$的生成子图,但是只包括满足$$l(x) + l(y) = w(x, y)$$的边$$(x, y)$$ 其中$$l(x)$$是可行顶标,必须满足$$l(x) + l(y) \geqslant w(x, y)$$ 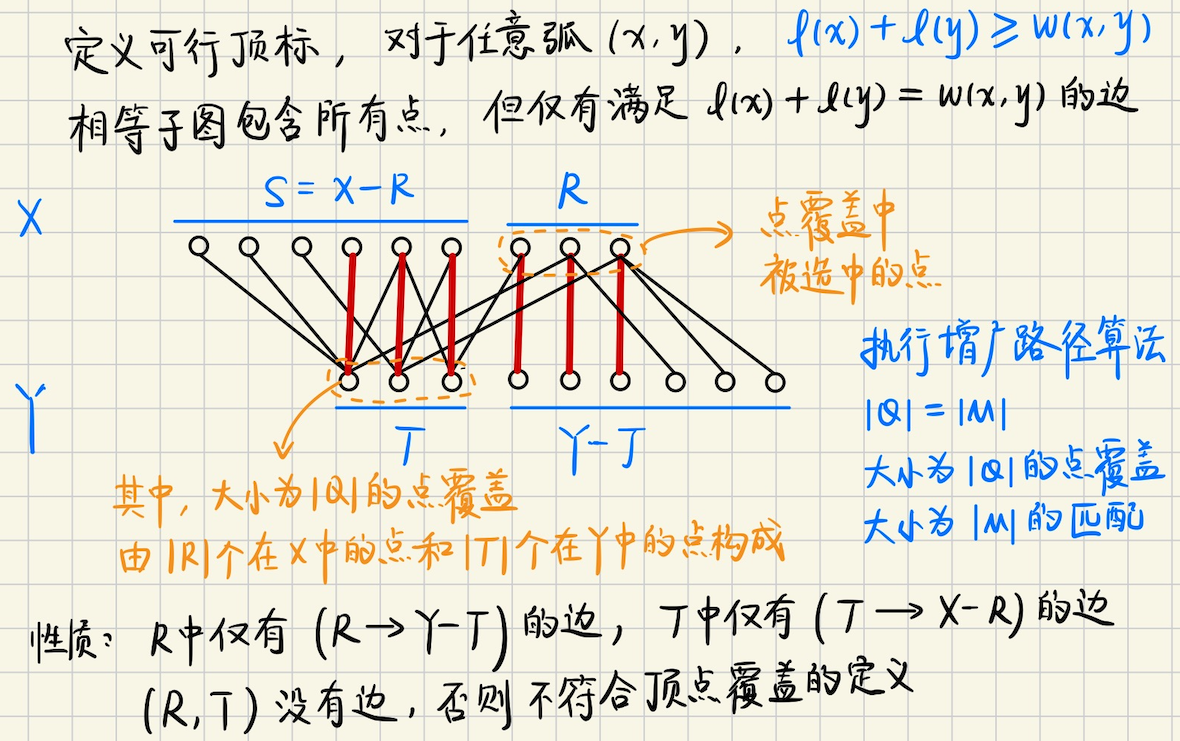 **算法思路** 不难想到,任意构造一个可行顶标,比如$$Y$$的顶标是$$0$$,$$X$$的顶标取从它出发的所有边的最大权值 然后取相等子图的最大匹配 如果存在完美匹配,那么算法终止,否则修改顶标,使得相等子图的边变得更多,则有更大机会存在完美匹配 **怎么修改顶标呢?考虑一些性质** 1.$$(X-R, Y-T)$$是没有边的,否则可以继续增广,因为$$R$$已经是增广路径算法找到的,$$\in X$$的最大点覆盖了 另外,$$(R, T)$$的边均为非匹配边,因为$$R, T$$都是$$\in |Q|$$的点覆盖 因为`最小点覆盖 = 最大匹配`,点覆盖中的任意两个点,都是非匹配边 2.令$$S = X-R$$,在相等子图上执行增广路径算法,考虑**匹配边**$$(S, T) \leftarrow (X-R, T)$$ 怎么修改顶标呢?首先要保证**原来的匹配边**$$(S, T)$$不会离开相等子图 可以考虑将$$S$$中所有点的顶标$$-\delta$$,同时$$T$$中所有点的顶标$$+\delta$$ 这样,原来相等子图中没有$$(S, Y-T)$$的边,将$$S$$中的顶标减小一定的数$$\delta$$之后 就可能有$$(S, Y-T)$$的**新边加入相等子图**,不断调整顶标,使得相等子图中的边尽可能多 3.那么,接下来的问题主要就是,$$\delta$$应该取多少? 对于相等子图,必须保证$$l(x) + l(y) \geqslant w(x, y)$$恒成立 首先,原来的相等子图,$$(S, T): \quad l(x) + \delta, \ l(y) - \delta$$,其中$$l(x) + l(y)$$是不变的 仍然能够保证$$l(x) + l(y) \geqslant w(x, y)$$ 现在考虑将新边$$x \in S, y \in Y-T$$加入相等子图,是否仍然保持恒成立?实际上 ```math \displaystyle \begin{cases} l'(x) = l(x) - \delta \\ l'(y) = l(y) \end{cases} ``` 那么我们需要$$l'(x) + l'(y) = l(x) - \delta + l(y) \geqslant w(x, y)$$恒成立 也就是说,我们要保证$$\delta \leqslant l(x) + l(y) - w(x, y)$$恒成立 我们取$$\delta = \min(l(x) + l(y) - w(x, y))$$即可 **匈牙利算法** 给$$T$$中的每个点$$y$$定义松弛量$$\text{slack}(y) = \min\\{l(x) + l(y) - w(x, y)\\}$$ 在算法执行的时候,维护相等子图的$$(S, T)$$,迭代的时候考虑$$T'$$中的点 令$$\delta = \min \\{\text{slack}(y), \quad y \in Y-T \\}$$,继续增广 ### 算法实现 如果边$$(x, y)$$加入相等子图,那么有如下两种情况 情况一,如果$$y$$未浸润,那么找到增广路 情况二,如果$$y$$已经和$$S$$中的点$$yx(y)$$匹配,那么将$$yx(y), y$$分别加入$$S, T$$中 为了实现匈牙利算法,还需要定义一些东西 首先是,对于$$x \in S$$,枚举$$y \in Y$$中的每个节点 定义**松弛量**$$\text{slack}(y) = \min \\{lx(x) + ly(y) - w(x, y)\\}$$ 实际松弛的时候,我们用`visy(y) = {1 or 0}`来标记$$y$$是在$$T$$集中,还是$$Y-T$$集中 根据之前的分析,新加入**相等子图**的边$$(x, y)$$,满足$$x \in X, y \in Y-T$$ 并且有$$lx(x) + ly(y) = w(x, y)$$ 另外还有,相等子图中,$$\text{slack}(y) = \min \\{lx(x) + ly(y) - w(x, y) \\}$$ 每次迭代中,**新加入**的每个$$x \in S$$,都可能会对$$\text{slack}(y)$$有影响 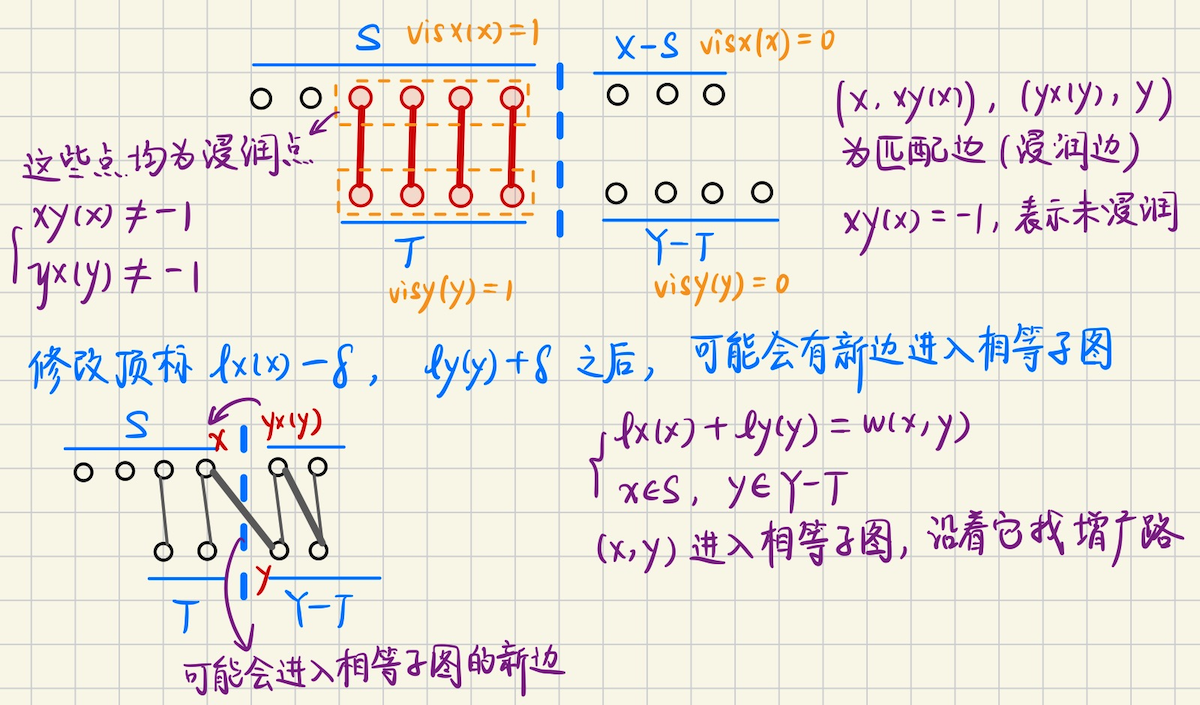 > 用 bfs 来实现匈牙利算法 **基本算法框架** 1.迭代$$nx$$次,每次迭代都尝试找出**一条**增广路$$(ex, ey)$$,具体怎么找呢? 2.和朴素匈牙利算法框架一样,一开始时候`visx, visy, p, slack`数组清空 ```bash visx.assign(nx, 0), visy.assign(ny, 0) slack.assign(ny, +infty) p.assign(nx, -1) ``` 先扩张$$S$$集,把未浸润的点,满足$$xy(x) = -1$$的$$x$$进队列(相当于`dfs(x)`) 然后进行`bfs`,每次取队头元素 3.注意到此时队列中的元素,都是满足$$xy(x) = -1$$的未匹配点,如果能够在**相等子图**中找到$$y \in Y$$ 并且$$yx(y) = -1$$,那么$$(x, y)$$就是增广路,具体来说 考虑所有$$y \in Y-T$$(即`visy(y) = 0`)的点$$y$$,如果$$lx(x) + ly(y) = w(x, y)$$,那么$$(x, y)$$边属于相等子图 若$$y$$未浸润,$$yx(y) = -1$$,那么$$(ex, ey) = (x, y)$$,找到了增广路了,退出这一轮迭代 若$$y$$已经和$$yx(y)$$**匹配**,按朴素匈牙利做法,$$dfs(x) \to dfs(yx(y))$$(看看从`yx(y)`出发能不能找到`vis = 0`的邻居) 这里用`bfs`实现,则需要将`yx(y)`**进队列**,同时按照`dfs`的做法,要标记`visx(yx(y)) = visy(y) = 1` 另外新进入队列的`yx(y)`,要用它来更新`slack`数组  4.如果这样做,队列都清空了,遍历了一遍仍然找不到增广路怎么办?考虑**修改顶标** 修改顶标的方法如上面分析的那样,$$\delta = \min(\text{slack}(y), \quad y \in Y-T)$$ ```bash for y in Y, if visy[y] == 0: delta = min(delta, slack[y]) for x in X: if visx[x] == 1: lx[x] -= delta for y in Y: if visy[y] == 1: ly[y] += delta else slack[y] -= delta ``` 修改完顶标之后,$$y \in Y-T$$中,能进入相等子图的边,满足$$\text{slack}(y) = 0$$ 并且$$(slackx(y), y)$$这个相等子图的边,可能是增广路径,具体是不是呢?和之前的做法一样 若$$y$$未浸润,即`yx[y] == -1`,那么$$(ex, ey) = (slackx(y), y)$$找到了增广路,退出迭代 若$$y$$已经和$$yx(y)$$匹配上了,同样需要`dfs(yx(y))`,看看有没有`vis = 0`的点,可以继续增广 用`bfs`来模拟,就是将`yx(y)`进队列,同时`p( yx(y) ) = slackx(y)`这是用来**回溯的** 依次更新`visx(yx(y)) = visy(y) = 1`,同时用`yx(y)`来更新`slack(y)` > 接下来考虑如何统计最大权,即匹配边的权值和   模拟`dfs`的回溯,$$x \to p(x)$$,$$y \to ty$$,依次把匹配边的权值加上 ```bash 迭代,权值代价,从上一次迭代,转移过来 costs[ cur + 1 ] = costs[cur] 一开始的时候,令 (x, y) = (ex, ey),并且端点处,新加入的边默认是匹配的 costs[cur + 1] += w(x, y) 如果发现 xy[x] != -1,那么需要交错路取反,之前的 (x, xy[x]) 要从匹配的,改成非匹配的 costs[cur + 1] -= w(x, xy[x]) 然后令 ty = xy[x], xy[x] = y, yx[y] = x,更新当前的匹配边 继续回溯,x = p[x], y = ty ```
看完文章有啥想法
发布评论
目录
[[ item.c ]]
11 人参与,0 条评论