算法小站
首页
wiki
新鲜事
文章搜索
网站导航
回忆录
首页
wiki
新鲜事
文章搜索
网站导航
回忆录
登录
注册
算法基础
搜索
数据结构
字符串
数学
图论
动态规划
计算几何
杂项
wiki 主题
算法基础
二维偏序
高维前缀和
树上差分
中位数定理
栈和队列
区间加等差数列
EGZ定理
搜索
数据结构
线段树
线段树单点修改
线段树区间修改
动态开点线段树
线段树的合并(一)
线段树的分裂
线段树的合并(二)
可持久化线段树
树链剖分
平衡树
FHQ-Treap
珂朵莉树
分块
位分块
根号分治
虚树
字符串
回文串
回文树
数学
组合计数
二项式定理
生成函数(一)
FFT
多项式与形式幂级数
同余与模
同余与模的应用
同余与模的概念
特殊的数
斯特林数
斯特林数相关的恒等式
斯特林数的综合应用
FFT的应用
整除分块
min-max容斥
图论
图的连通性
有向图的强连通分量
无向图的割点割边和双连通分量
图的连通性综合
流和匹配
最大流
最大流的一些应用
最小割
费用流
带上下界的网络流
二分图匹配
二分图最大权匹配
网络流综合
图论杂项
最大团搜索算法
树上问题
kruskal重构树
kruskal重构树的一些问题
最小生成树
最短路
差分约束
2-SAT
基环树
动态规划
背包模型
dp优化
凸壳优化
单调队列优化
计算几何
凸包(一)
杂项
启发式合并
高精度
一些经典问题
约瑟夫环
曼哈顿距离
多重集合的排列组合
蔡勒公式
排列与置换
Catalan数与格路径
主题名称
是否为父主题
是否为其添加wiki文章
取 消
确 定
选择主题
修改主题名称
修改父主题
修改wiki文章
取 消
删 除
修 改
算法基础
搜索
数据结构
字符串
数学
图论
动态规划
计算几何
杂项
数据结构
线段树
线段树单点修改
线段树区间修改
动态开点线段树
线段树的合并(一)
线段树的分裂
线段树的合并(二)
可持久化线段树
树链剖分
平衡树
FHQ-Treap
珂朵莉树
分块
位分块
根号分治
虚树
[[ item.c ]]
1
1
可持久化线段树
## 主席树 ### 区间第k小 假设有序列 $$A = \left<a_1, a_2, \cdots, a_n \right> = \left<-2, -6, 12, 3 \right>$$ 如何找区间第 k 小? * 先将序列离散化成 $$[2, 1, 4, 3]$$,`for i = [1, n]` **对每一个`i`都建一棵区间 $$[1,i]$$ 的线段树**,这样在每个$$i$$上查询$$[1, i]$$的第$$k$$小,复杂度$$O(\log n)$$ 对于第$$i$$棵线段树,可以考虑在第$$i-1$$棵线段树上做修改 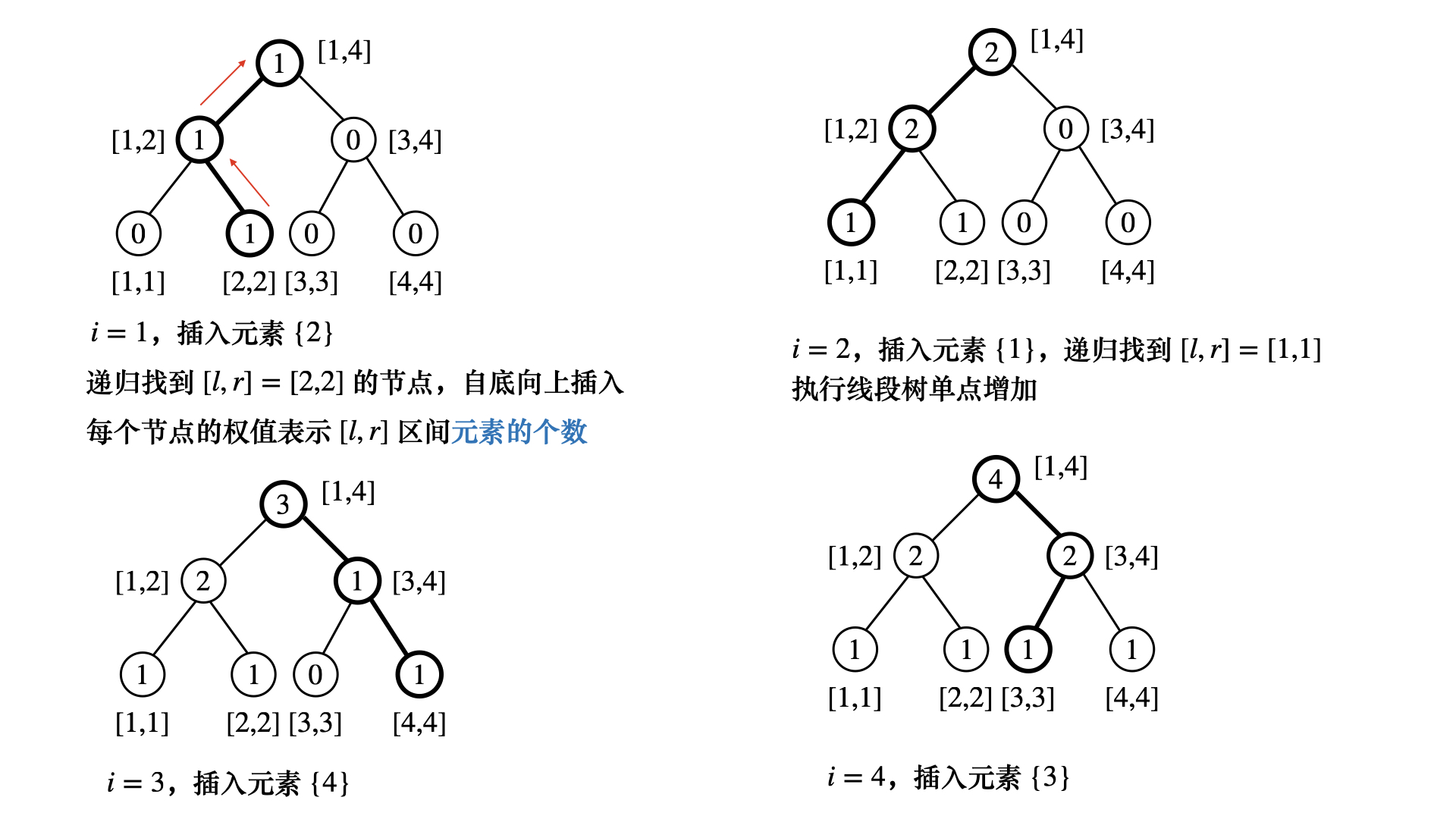 * 定义主席树**节点权值**,在区间$$[l, r]$$中有多少个元素? > 注意到第$$i$$棵线段树和第$$j \ (i < j)$$棵线段树结构完全一样,区别仅仅是权值不同 根据**前缀和**,询问$$[L, R]$$,`tr[R] - tr[L-1]` 就表示$$[L, R]$$中有多少个元素 > 实际上`tr[P] = tr[R]-tr[L-1]`也可以看作一棵线段树,结构一样,权值为对应点权值相减 * 这样就等于在 `tr[P]` 这棵线段树中找第 $$k$$ 小,利用二分思想 如果`tr[P].left`的元素**个数**$$\geqslant k$$,递归在`tr[P].left`中找第$$k$$小 否则,令$$k' = k- \text{cnt}(tr[P].left)$$,在`tr[P].right`中找第$$k'$$小 > 另外,怎么保证**函数式做差**得到的线段树`tr[P] = tr[R] - tr[L-1]`恰好对应区间 $$[L, R]$$ 呢? 注意到线段树维护**元素个数**,这样对于线段树$$i$$,只要保证 $$[1,\cdots, i]$$ 中的点全部都有对应的值,$$[i+1,\cdots,n]$$ 中点未被插入,值是空的 **对线段树进行可持久化** 综上分析可以发现,上述算法时间复杂度很好,但是空间复杂度是$$O(n^2)$$的 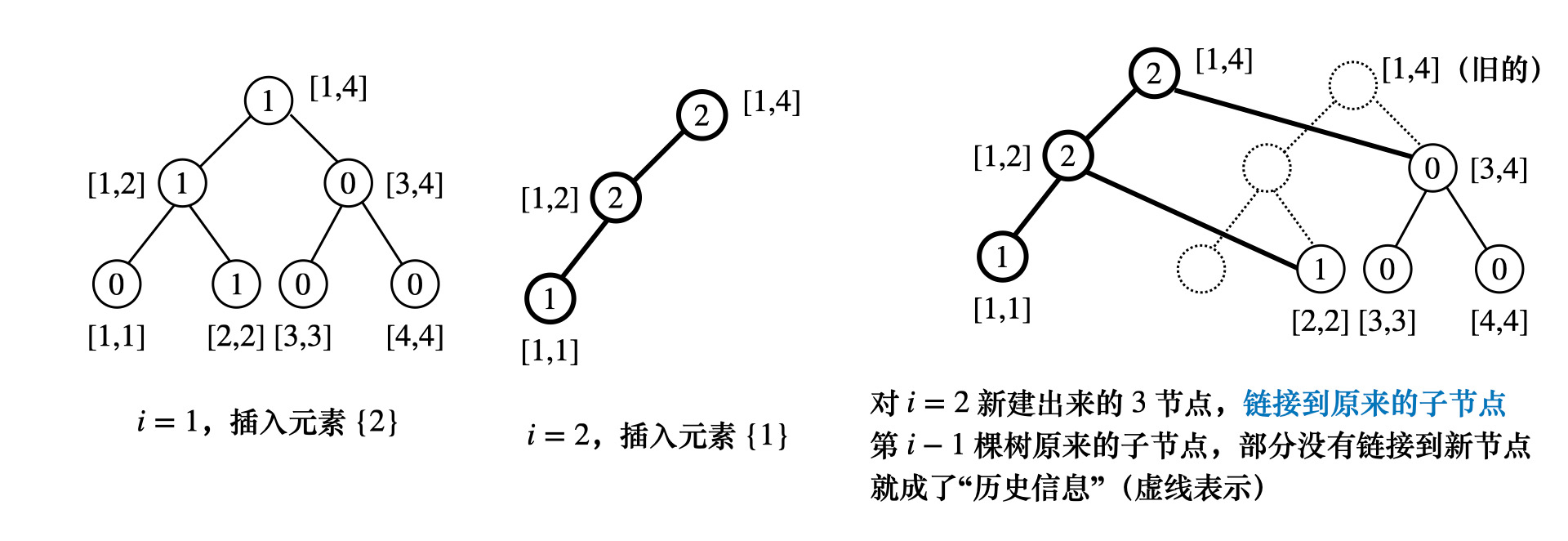 注意到第$$i-1$$棵线段树到第$$i$$棵线段树,只有**加粗部分**不一样 加粗部分即**发生修改的路径**,只需要存储**修改路径**上的节点就可以了 **[K-th number](https://www.spoj.com/problems/MKTHNUM/en/)** **[第 K 大数](https://vjudge.net/problem/SPOJ-MKTHNUM)** 主席树需要保存树**历史版本的根的指针**,这里用`ver[i]`表示第`i`个版本树的根的**编号** > 主席树如何维护序列? 和线段树类似,把主席树节点保存在`vector<Node> nd` 中 序列$$a_i$$对应第$$i$$个**版本**的线段树,它的根节点编号是`ver[i]` (实际上,根节点是`nd[ ver[i] ]`,可以遍历这棵树了) * 主席树维护序列`a[1...n]`,执行`insert(pid, l, r, pos, f)` 其中`pid`表示**历史版本**,`l, r`表示**线段树节点对应区间**,`pos`是**叶节点**的值 `f`是映射规则,将`pid`这棵线段树修改得到`nid`,$$nid = f(pid)$$,即函数式线段树映射 `for i = [1, n]` 遍历序列,基于第$$i-1$$个**版本**的线段树执行**插入**$$a_i$$ * 在`ver[i-1]`中找到 $$a_i$$ 对应的**叶子结点**`mp[ a[i] ]`(离散化之后对应的值) (方法和普通线段树差不多,根节点 `ver[i-1]`表示区间$$[1, n]$$,往下递归) * 实际上,`ver[i-1]`的根节点到叶节点形成一条**路径**$$path$$,对于`ver[i]`, 从根节点到叶节点路径需要**更新**为$$path^{\prime}$$,实际上主席树执行映射$$path^{\prime} = f(path)$$ 对应地,路径上每一个点对应更新,`nd[ nid ].info = f( nd[ pid ].info )` 如果叶节点`pos`在左区间,递归更新 `nd[nid].l` 左子树**指针**,否则更新右子树**指针** (将指针指向一个新建出来的节点,这样每次更新只新建了$$O(\log n)$$个节点) > 主席树如何求区间$$[l, r]$$第$$k$$大元素? 注意到**插入**节点的时候,节点**计数器**`cnt`, 从叶子结点到根节点路径上,所有点的`cnt += 1` * 主席树区间查询 一般指查询第$$[l, r]$$第$$k$$大,根据之前的分析 针对`nd[ ver[r] ] - nd[ ver[l-1] ]`,即 **两棵线段树做差**结果来查询 两个指针**同步遍历**线段树`nd[lid], nd[rid]`,同步找叶子结点 * 和普通`BST`不一样的是,我们需要对节点做**运算**,比如 `op(nd[rid], nd[lid])` > 这里**左儿子**的元素个数为`cnt` 实际上`cnt`统计了**左儿子+其子树**的节点个数 由此记 **`count = nd[ nd[rid].l ].cnt - nd[ nd[lid].l ].cnt`**(两个指针要**同步**遍历) 如果 `count >= k`,那么往左子树递归找第 `k` 大 否则往右子树递归找第 `k-count` 大 ### 主席树算法实现 #### 模版定义 ```bash template<class S, class F, S (*upd)(F, S), S (*e)() class T, int MAXN> wseg_tree ``` * `S info` 是主席树维护的信息的数据类型 * `F f` 是**算子**的数据类型,比如第$$i-1$$个版本更新到$$i$$,对应路径上的点都加上`5LL` 那么 `(F f)` 对应为 `(F f) = (long long 5LL)`,这个算子是如何赋值的呢? 可以在**构造函数**中给算子赋值,比如 `wseg_tree<ll, ll, ..., > tr(a, 5LL)` * `upd(F f, S x)`是函数式线段树映射,比如 `ver[i-1] -> ver[i]` 更新的时候, 路径上的点都要**更改**,假设`ver[i-1]`的点为`x` ```bash ver[i-1] --> ver[i] x ---> upd(f, x) ``` 举个例子,比如统计一个点及其子树点的个数`cnt`,可以定义 `ll upd(ll f, ll x) { return x+f; }` `f` 这个算子的值同样可以在构造函数中初始化,`wseg_tree<ll, ll, ...> tr(a, 1LL)` * `e()` 权值线段树中,`info`信息的初始值 * `class T` 是原始数据类型,比如主席树维护 `A[1...n]`,`T`就是`A`的数据类型 * `MAXN`是主席树节点数量,一般取 `n<<5` #### 构造函数,插入与查询 ```bash wseg_tree(const vector<T>& a, F f) ``` * `a` 是原始数据,`a[1...a.size()-1]` 对应的线段树根节点的**编号**为 `ver[1, 2, ..., a.size()-1]`,`ver[0]`是哨兵 * 每一棵树的根节点维护区间 `[1, _n] = [1...idx]`,其中`idx`是离散化之后节点的个数 * `f` 为算子的值,比如给每个节点都加上 `9LL`,那么 `F f` 对应为 `9LL` ```bash int insert(int pid, int l, int r, int pos, F f) ``` * 函数返回值是新建节点的**编号** `nid` * `pid` 是**历史版本**,`nid`就是基于这个历史版本`pid`进行修改得到的 * `l, r` 是主席树节点表示的区间,比如根节点就是 `[1, _n]` > 注意这里的 `_n` 是离散化之后节点的个数 * `pos` 是叶子结点的值,一般是离散化之后的值 比如插入`a[i]`,那么 `pos = mp[ a[i] ]` * `f` 是更新所用到的**算子** ```bash int queryK(int lid, int rid, int l, int r, int K) ``` * `lid, rid` 为查询区间的左右端点**对应的线段树**,它们的根节点**编号** 比如查询 `[L, R]`,那么要执行 $$tr(R) - tr(L-1)$$,可以取 `lid = ver[L-1], rid = ver[R]` * `l, r` 是线段树节点所表示的区间,比如根节点对应 `[1, _n]` ## 主席树的应用 ### 区间小于等于 k 的数有多少 **[HDU4417](http://acm.hdu.edu.cn/showproblem.php?pid=4417)** **[Super Mario](https://vjudge.net/problem/HDU-4417)** **问题描述** 给定一个序列 $$a_1, \cdots, a_n$$,给定 $$m$$ 个询问,每个询问 `l r k`,查询区间 $$[l, r]$$ 内 $$\leqslant k$$ 的整数有多少个 **算法分析** 先来看一个问题,对于第$$i$$棵线段树,它的某个**叶子结点**$$x$$有哪些信息? > 线段树`ver[i]`,只维护了**前缀** $$[a_1, \cdots, a_i]$$ 中的所有数 考虑权值,从 $$x$$这个叶节点往根节点**追溯** > 如果**一直从左边往上**追溯到点$$u$$,那么点$$u$$维护了前缀$$a[1, i]$$中 权值在$$[1, x]$$区间内点的个数 > 如果在追溯的时候,存在**右边往上**的路径,那么点$$u$$维护了一些权值 $$> x$$ 的点 由此,对区间 $$[l,r]$$ 查询 $$\leqslant k$$ 的节点个数 可以检查函数式线段树 $$tr(r) - tr(l-1)$$,具体来说 * 将 `k` **离散化**成叶子结点 `x`,从根节点递归找到叶节点`x` * 如果 `x <= mid`,意味着当前区间还有一部分数可能权值 $$\geqslant x$$,继续递归左子树寻找 * 如果 `x > mid`,那么当前区间**左子树覆盖的所有点权值都**$$< x$$ (实际上,左子树维护权值在 $$[1, mid]$$ 的点的个数) 所以 `ans += nd[ nd[r].l ].cnt - nd[ nd[l-1].l ].cnt` 还有一部分 $$mid < [\cdots] \leqslant x$$ 的数,递归到右子树查询 两部分加起来就是答案 ### 统计区间内有多少个不同数 **[Sequence II](https://vjudge.net/problem/HDU-5919)** **问题描述** 给定序列$$a_1, \cdots, a_n$$ 和 $$m$$ 个询问,每次询问给定 `l r k`,对区间 $$[l, r]$$ 中的数,只统计**它们第一次出现**的位置 要求回答区间内有多少个不同的数?假设区间有 $$K$$ 个不同的数, 那么这$$K$$个不同数的下标为 $$p_1, p_2, \cdots , p_K$$,需要回答 ```math p_{\lceil \frac{K}{2} \rceil} ``` 是多少?即第 $$\lceil\frac{K}{2} \rceil$$ 个数的**下标** **算法分析** > 注意,这里我们只需要求出第`m`个数的下标,并不需要知道具体值 假设`val`出现在两个位置`{i, j}`,`pos = {i+1, ..., j-2, j-1, j}`这些位置 `val`第一次出现的位置都记为`j`,`j`有贡献,这些位置对应的版本`pos = j`都要`+1` 所以考虑**针对下标,倒着遍历,开主席树** `i`这个版本呢? 第一次出现 val 的位置就不是`j`了,而是`i`,在`j`这个位置`-1` 并且在`i`这个位置`+1` > 怎么统计答案 查询`[li, ri]`有多少个不同的数,因为我们是倒着做的 `[0...li-1]`的信息没有,`li`版本就存了`[li...n]`哪些下标有`1`的贡献 因为一个数只记一次,把这些`1`加起来就是区间有多少个不同的数 对于`[li, ri]`,那么$$\leqslant ri$$才是有效的`1`,算$$\leqslant ri$$有多少个数 至于第$$m$$个数的下标? 因为我们所有数的值都是`1`,也就是找第`m`个`1`,`findKth(m)`即可 ## 主席树标记永久化 **什么是标记永久化**(带懒标记的主席树) 在主席树中下放`Lazy Tag(push_down)`时,**千万记得要新建左右儿子节点**(不能直接修改原有的左右儿子,否则会破坏历史版本) > 怎么处理懒标记 1)不下放: 懒标记就在当前节点“安家落户”了,永远不往下传。 路过就更新: 当我们修改区间`[x, y]`时,只要路过节点`[l, r]`,就直接把贡献加到当前节点的`info`上 **先 fork 一份出来**,`int q = copyNode(p)` **如果完全包含,打上永久标记,并更新`t[q].tag, t[q].info`** 懒标记的含义是,**已经修改,但尚未下传** **如果是部分覆盖**,原有的`copyNode(p)`上的`info`不能直接用了,递归下去修改儿子 2)查询时带着走,从根节点往下走,手里揣着一个**“累加器`accum`”** 把沿途遇到的所有祖先的懒标记收集起来,到了目标区间一并算上 **[HDU4348](http://acm.hdu.edu.cn/showproblem.php?pid=4348)** **[To the moon](https://vjudge.net/problem/HDU-4348)** **问题描述** 给定$$a_1, \cdots, a_n$$,给定$$m$$个操作,并且有时间戳 `C L R d` 将 `[L, R]` 所有数都`+d`,时间戳`t += 1`,只有这个操作会改变`t` `Q L R` 查询区间和 `H L R t` 查询时间`t`的历史区间和 `B t` 返回时间`t`,`t` 之后的操作全部清空 **算法分析** 对每个时间戳建一个版本的线段树,按主席树的方法来处理 ```bash int modify(int p, int l, int r, int x, int y, const Tag &v) { 先 fork 一份出来 int q = copyNode(p); if x <= l and r <= y: 完全包含,打上永久标记,并且更新自己的 Info t[q].tag.apply(v), t[q].info.apply(v, l, r); return q; int mid = (l + r) >> 1; // 如果未完全覆盖,原有的 copyNode(p) 上的 info 不能直接用了 // 递归下去修改儿子,fork 儿子,然后修改 if (x <= mid) t[q].lc = modify(t[p].lc, l, mid, x, y, v) if (y > mid) t[q].rc = modify(t[p].rc, mid + 1, r, x, y, v) pull(q, l, r); return q; } ``` > 处理查询,用一个**累加器**带着标记往下走 ```bash Info rangeQuery(int p, int l, int r, int x, int y, Tag accum) { if (!p) return Info{} if (x <= l and r <= y) { Info res = t[p].info; // 把祖先塞过来的包裹(标记)结算掉 res.apply(accum, l, r); return res; } int mid = (l + r) >> 1; // 将当前节点的标记装进包裹,传给儿子 Tag curAccum = accum; curAccum.apply(t[p].tag) Info res{}; bool hasLeft = false; if (x <= mid) { hasLeft = true; res = rangeQuery(t[p].lc, l, mid, x, y, curAccum); } if (y > mid) { Info r_res = rangeQuery(t[p].rc, mid + 1, r, x, y, curAccum); res = hasLeft ? (res + r_res) : r_res; } return res; } ``` ## 主席树树上查询 **[Count on a tree](https://www.spoj.com/problems/COT/en/)** **[SPOJ COT](https://vjudge.net/problem/SPOJ-COT)** **问题描述** 给定 $$N$$ 个节点的树,每个节点有一个权值,有 $$m$$ 个询问,每个询问 `u v k`,询问$$u\to v$$ (包括$$u, v$$)路径第$$k$$小的点的权值 **算法分析** > 能不能通过`dfs`序将本问题转换成序列问题?`dfs`序能求出什么? 如果求树上某个节点的**子树**(包括这个节点)的第$$k$$小,是可以考虑`dfs`序的 因为`dfs`序能保证**子树**对应序列中**一段连续区间** 用`l[u]`表示第一次访问`u`的时间戳,`r[u]`表示回溯完的时间戳,那么$$[l_u, r_u]$$ 就对应子树所在的区间 > 本题求$$u \to v$$树链上的第$$k$$小,并不能用`dfs`序 因为`u -> LCA -> v`路径在`dfs`序上**不一定连续** 这里解决树链问题,用**树上差分 + 主席树** 记$$f(u)$$为$$u$$到根节点路径上点的个数,那么$$u \to v$$路径上实际的点个数为 $$f(u) + f(v) - 2f(\text{lca}) + \text{lca}$$,如果记$$\text{lca}$$的父亲节点为$$\text{plca}$$ 点的个数实际上是 $$f(u) + f(v) - f(\text{lca}) - f(\text{plca})$$ **算法实现** 在树上建主席树和依据序列建主席树略有不同,需要在`dfs(u, pa)`,第一次访问`u`节点的时候 `ver[u] = tr.insert(ver[pa], 1, _n, mp[ a[u] ])`,即根据父节点的版本,创建当前节点 > 注意,树上建主席树,会用到**函数式线段树查询** 比如本例中 ```bash int g(array<int, 4> arr) { auto [t1, t2, t3, t4] = arr; return tr.nd[ tr.nd[t1].l ].cnt + tr.nd[ tr.nd[t2].l ].cnt - tr.nd[ tr.nd[t3].l ].cnt - tr.nd[ tr.nd[t4].l ].cnt; }; ``` $$f(u)+f(v)-f(lca)-f(plca)$$ 实际上用到了`4`个参数,调用的时候 ```bash int res = tr.query<4, g>(Arr{ver[u], ver[v], ver[lca], ver[plca]}, 1, tr._n, k); template<int M, int (*g)(array<int, M>)> int query(array<int, M> arr, int l, int r, int K) // M是函数式线段树查询,需要用到的参数数量,本例 M = 4 // g 是函数式查询中,对应的查询表达式 ``` ## 主席树随机化哈希 **[Codeforces Round 837 (Div. 2) F. Hossam and Range Minimum Query](https://codeforces.com/contest/1771/problem/F)** **问题描述** 给定一个长度为$$n$$的数组$$a$$,以及$$q$$个询问$$[L, R]$$ 询问区间中出现次数为奇数的数,**最小的一个**,如果不存在,返回`0`,强制在线 ### 随机化算法 区间第`1`小,不难想到用主席树,那么如何处理**出现次数为奇数**这个条件呢? 不难想到可以用**异或操作**作为条件判断,那么大致算法如下 建主席树的时候,可以考虑离散化,`a -> mp(a)`,离散化之后建主席树 这里对于离散化之后的点,给一个随机化哈希值`hs( mp(a) ) = mrand()`,并且把这个值写入主席树节点的`info`中 哈希值异或和为`0`,说明区间所有数都出现偶数次,否则就存在出现次数为奇数的数 > 那么`info`中的值怎么维护呢?实际上只需要自定义`upd`操作即可 ```bash unsigned int upd(rnd, info) { return rnd ^ info; } 主席树自顶向下,边插入边修改 基于历史版本修改的过程,保存了区间所有数的异或 和普通线段树对比,普通线段树需要 pull(ls, rs) 操作,把子区间所有信息都统计起来 主席树,基于 ver[i-1] -> ver[i] 版本的时候,新插入一个数,是自顶向下的 从上到下,从最大的区间到子区间,节点都会添加这个新的 info 所以主席树,一般来说需要用 upd(f, info) 来维护信息 ver[i-1] -> ver[i] 是怎么变化的?添加了哪些数? ``` > 怎么查询呢? 和主席树查询大同小异,对于区间`[L, R]`,我们考虑`nd[R].info ^ nd[L-1].info`,这就是这个区间内所有数的异或和了 先检查左半边,如果左半边的异或和为`1`,就走左半边,否则走右半边 左半边的异或和也不难求,`nd[ nd[R].l ].info ^ nd[ nd[L-1].l ].info` ### 随机化哈希算法实现 ```bash wseg_tree { // 其他代码忽略 template<typename T> void build(const vector<T> &a, map<T, int> &mp, vector<T> &rm, map<int, int> &rnd) { int tot = 0; for (int i = 1; i < (int)a.size(); i++) mp[a[i]] = 0; for (auto &p : mp) { p.second = ++tot, rm[tot] = p.first; } for (int i = 1; i < (int)a.size(); i++) { auto x = mp[a[i]]; if (!rnd.count(x)) rnd[x] = mrand(); } _n = tot; vector<Node> ((int)a.size()<<5, Node{}).swap(nd); vector<int> ((int)a.size()+5, 0).swap(ver); for (int i = 1; i < a.size(); i++) { ver[i] = insert(ver[i-1], 1, _n, mp[a[i]], rnd[ mp[a[i]] ]); } } // 以下是查询 // // 查询满足 f(r) - f(l-1) = ??? 条件的,min_left 位置 template<int (*f)(S, S)> int min_left(int lid, int rid, int l, int r) { if (l >= r) { if (f( nd[lid].info, nd[rid].info ) == 0) return -1; return l; } int mid = (l + r) >> 1; int val = f( nd[ nd[lid].l ].info, nd[ nd[rid].l ].info ); if (val != 0) return min_left<f>(nd[lid].l, nd[rid].l, l, mid); else return min_left<f>(nd[lid].r, nd[rid].r, mid+1, r); } } // 定义 f 运算 int upd(int rnd, int info) { return rnd ^ info; } int id() { return 0; } int f(int infol, int infor) { return infol ^ infor; } void solve() { map<int, int> mp, rnd; vector<int> rm(n+5, 0); wseg_tree<int, int, upd, id> tr(0); tr.build(a, mp, rm, rnd); // query [l, r] auto res = tr.min_left<f>(tr.ver[l-1], tr.ver[r], 1, tr._n); ans = rm[res] } ``` ## 主席树算法实现 ### 区间第 k 大 ```bash template<class S, class F, S (*upd)(F, S), F (*id)()> class wseg_tree { public: struct Node { S info; int cnt; int l, r; }; int idx = 0; int _n = 0; // 这里的 _n 表示根节点的值域范围 [1, _n] // 也就是离散化之后,tr 叶子结点表示的数是 [1, 2, ..., _n] // ver[i] 表示第 i 个版本的树的根的编号 vector<Node> nd; vector<int> ver; explicit wseg_tree(int n) : _n(n) { idx = 0; nd = vector<Node> (_n<<5, Node()); ver = vector<int> (_n+5, 0); } // 构造函数,用于数组 a 的离散化,同时构建函数式线段树 // f 表示从旧版本,pid -> nid 过程中,node[nid] = f( node[pid] ) template<typename T> void build(const vector<T> &a, map<T, int> &mp, vector<T> &rm, F f) { idx = 0; rm = vector<T> ((int)a.size()+5, T{}), mp.clear(); for (int i = 1; i < (int)a.size(); i++) mp[a[i]] = 0; for (auto &p : mp) { p.second = ++idx, rm[idx] = p.first; } _n = idx; nd = vector<Node> ((int)a.size()<<5, Node{}); ver = vector<int> ((int)a.size()+5, 0); for (int i = 1; i < a.size(); i++) { ver[i] = insert(ver[i-1], 1, _n, mp[a[i]], f); } } // 0 是哨兵节点 int insert(int pid, int l, int r, int pos, F f) { if ( !(l <= pos && pos <= r) ) return 0; const auto &pre = nd[pid]; int nid = ++idx; nd[nid] = Node{ upd(f, pre.info), pre.cnt+1, pre.l, pre.r }; if (l >= r) return nid; int mid = (l + r) >> 1; if (pos <= mid) nd[nid].l = insert(pre.l, l, mid, pos, f); else nd[nid].r = insert(pre.r, mid+1, r, pos, f); return nid; } // [l, r] 是待查询区间,线段树的叶子结点满足 l >= r // 叶子结点 x,离散化后的数对应的就是 x int queryK(int lid, int rid, int l, int r, int K) { if (l >= r) return l; const auto &le = nd[lid]; const auto &ri = nd[rid]; int cnt = nd[ri.l].cnt - nd[le.l].cnt; int mid = (l + r) >> 1; if (K <= cnt) return queryK(le.l, ri.l, l, mid, K); else return queryK(le.r, ri.r, mid+1, r, K-cnt); } }; ll upd(ll f, ll x) { return f + x; } ll id() { return 0LL; } void solve() { int n, q; cin >> n >> q; vector<ll> a(n+1, 0); for (int i = 1; i <= n; i++) cin >> a[i]; map<ll, int> mp; vector<ll> rm(n+5, 0); wseg_tree<ll, ll, upd, id> tr(n); tr.build<ll>(a, mp, rm, id()); while (q--) { int l, r, k; cin >> l >> r >> k; auto ans = tr.queryK(tr.ver[l-1], tr.ver[r], 1, tr._n, k); printf("%lld\n", rm[ans]); } } ``` ### 区间小于等于 k 的数的个数 **[数数](http://oj.daimayuan.top/problem/464)** ```bash // 查询 [p1, p2] <= x 的数量 int countLeq(int p1, int p2, int l, int r, int x) { if (l > x or p1 == p2) { return 0; } // [l, r] 全部位于 x 一侧,整个区间都 <= x if (r <= x) return t[p2].info.cnt - t[p1].info.cnt; int mid = (l + r) >> 1; int res = countLeq(t[p1].lc, t[p2].lc, l, mid, x); if (x > mid) { res += countLeq(t[p1].rc, t[p2].rc, mid + 1, r, x); } return res; } int countLeq(int L, int R, int x) { // 如果 x 离散化之后是 0,没有任何元素 <= x,返回 0 if (x == 0) return 0; return countLeq(roots[L-1], roots[R], 1, n, x); } ``` ### 查询区间有多少个不同的数 ```bash // 查询区间有多少个不同的数,以及第 m 个数的下标 // 针对下标,倒着遍历,开主席树 // {i, j} 都出现了 val,l = {i+1, ..., j-2, j-1, j} 这些位置 // val 第一次出现的位置都是 j,j 有贡献,这些版本 pos = j 都要 +1 // i 这个版本呢? 第一次出现 val 的位置就不是 j 了,而是 i,在 i 这个位置 +1 template<class T> void build(const vector<T> &a) { int tot = a.size(); init(tot); roots.assign(a.size() + 5, 0); map<int, int> last; for (int i = a.size() - 1; i >= 1; i--) { auto rt = roots[i + 1]; if (last.contains(a[i])) rt = modify(rt, 1, n, last[a[i]], Info{-1}); rt = modify(rt, 1, n, i, Info{1}); roots[i] = rt; last[a[i]] = i; } } // 查询 [li, ri] 有多少个不同的数,因为我们是倒着做的 // [0...li-1] 的信息没有,li 版本就存了 [li...n] 哪些下标有 1 的贡献 // 因为一个数只记一次,把这些 1 加起来就是区间有多少个不同的数 // [li, ri],那么我们看 <= ri 的才是有效的 1,<= ri 有多少个数 // 第 m 个数的下标?因为我们所有数的值都是 1,也就是找第 m 个 1,findKth(m) 即可 void solve(int cas) { vector<int> a(n+1, 0); for (auto &x : a | views::drop(1)) cin >> x; PersistentSegtree<Info> tr; tr.build(a); vector<int> ans(m+5, 0); for (int i = 1; i <= m; i++) { int li, ri; cin >> li >> ri; // [li, ri] 有多少个不同的数 int K = tr.countLeq(0, tr.roots[li], 1, tr.n, ri); int m = (K + 1) / 2; int res = tr.findKth(0, tr.roots[li], 1, tr.n, m); ans[i] = res; } } ``` ### 标记永久化 ```bash ll mapping(ll f, ll info, PII seg, PII ask) { auto [l, r] = seg; auto [li, ri] = ask; if (li == -1) return info + 1LL * f * (r-l+1); return info + 1LL * f * (min(r, ri) - max(l, li) + 1); } ll comp(ll f, ll g) { return f + g; } lazy_wsegtree { //... int insert(int pid, int l, int r, const int li, const int ri, F f) { int nid = ++idx; nd[nid] = Node{ mapping(f, nd[pid].info, {l, r}, {li, ri}), nd[pid].l, nd[pid].r }; lazy[nid] = lazy[pid]; if (li <= l && r <= ri) { lazy[nid] = comp(f, lazy[nid]); return nid; } int mid = (l + r) >> 1; if (li <= mid) nd[nid].l = insert(nd[pid].l, l, mid, li, ri, f); if (ri > mid) nd[nid].r = insert(nd[pid].r, mid+1, r, li, ri, f); return nid; } // {-1, -1} 是哨兵,表示我们到达目标区间了 S query(int nid, int l, int r, const int li, const int ri, F accu) { if (li <= l && r <= ri) { S res = mapping(accu, nd[nid].info, {l, r}, {-1, -1}); return res; } accu = comp(lazy[nid], accu); int mid = (l + r) >> 1; S res = S(0); if (li <= mid) res += query(nd[nid].l, l, mid, li, ri, accu); if (ri > mid) res += query(nd[nid].r, mid+1, r, li, ri, accu); return res; } }; ``` ### 主席树树上查询 ```bash wseg_tree { typedef array<int, 4> Arr; int queryK(const Arr &arr, int l, int r, int K) { if (l >= r) return l; int mid = (l + r) >> 1; auto [u, v, lca, plca] = arr; // printf("dbg: %d %d %d %d\n", u, v, lca, plca); int cnt = nd[nd[u].l].cnt + nd[nd[v].l].cnt - nd[nd[lca].l].cnt - nd[nd[plca].l].cnt; Arr narr; (K <= cnt) ? (narr = {nd[u].l, nd[v].l, nd[lca].l, nd[plca].l}) : (narr = {nd[u].r, nd[v].r, nd[lca].r, nd[plca].r}); if (K <= cnt) return queryK(narr, l, mid, K); else return queryK(narr, mid+1, r, K-cnt); } }; void solve() { //.... auto dfs = [&](auto &dfs, int u, int pa) -> void { dep[u] = dep[pa] + 1; tr.ver[u] = tr.insert(tr.ver[pa], 1, tr._n, mp[ a[u] ], id()); for (auto v : G[u]) { if (v == pa) continue; up[v][0] = u; dfs(dfs, v, u); } }; // 输入 u, v, k,查询 u -> v 路径第 k 大 auto lca = LCA(u, v); auto plca = up[lca][0]; array<int, 4> arr = {tr.ver[u], tr.ver[v], tr.ver[lca], tr.ver[plca]}; auto res = tr.queryK(arr, 1, tr._n, k); printf("%lld\n", rm[res]); } ```
看完文章有啥想法
发布评论
fogsail
看看其他评论功能
2023-06-23 19:16:46
点赞(0)
回复(2)
zhangminchen @ fogsail
可以吧~
2023-06-23 19:17:07
点赞(0)
回复(1)
zhangminchen @ zhangminchen
自己回复自己看看
2023-06-23 19:17:15
点赞(0)
回复(0)
回复
zhangminchen
试试看~
2023-06-23 19:01:51
点赞(0)
回复(3)
zhangminchen @ zhangminchen
不错,考虑一下
2023-06-23 19:15:35
点赞(0)
回复(2)
fogsail @ zhangminchen
支持一个啦啦
2023-06-23 19:16:27
点赞(0)
回复(1)
fogsail @ fogsail
自己回复自己~
2023-06-23 19:16:34
点赞(0)
回复(0)
回复
目录
[[ item.c ]]
1737 人参与,7 条评论
fogsail
zhangminchen @ fogsail
zhangminchen @ zhangminchen
zhangminchen
zhangminchen @ zhangminchen
fogsail @ zhangminchen
fogsail @ fogsail