算法小站
首页
wiki
新鲜事
文章搜索
网站导航
回忆录
首页
wiki
新鲜事
文章搜索
网站导航
回忆录
登录
注册
算法基础
搜索
数据结构
字符串
数学
图论
动态规划
计算几何
杂项
2026年五月算法竞赛选题(一)
segtree beats, 博弈论,lcm,连通块,裴祖定 .....
[[ slider_text ]]
[[ item.c ]]
0
0
2026年五月算法竞赛选题(一)
发布时间
2026-05-13
作者:
秋千月
来源:
算法小站
## Codeforces Round 1049 ### E1 **[E1. Prime Gaming (Easy Version)](https://codeforces.com/contest/2140/problem/E1)** 有`n`堆石头,每堆石头必须个数,必须是$$[1, m]$$之间的整数,这里$$m \leqslant 2$$ 现在指定$$1 \sim n$$的一些下标记为好的,Alice 和 Bob 轮流玩,每一轮执行如下操作 任选一个好的下标$$1 \leqslant i \leqslant p$$(`p`是当前还剩下的堆数) 然后把$$i$$堆彻底移除,移除之后,剩余的堆拼接在一起并重新编号,保证`1`号一定是好下标 只剩最后一堆的时候,游戏结束,$$x$$表示最后剩下的石头数量 Alice 要最大化$$x$$,Bob 要最小化 **算法分析**  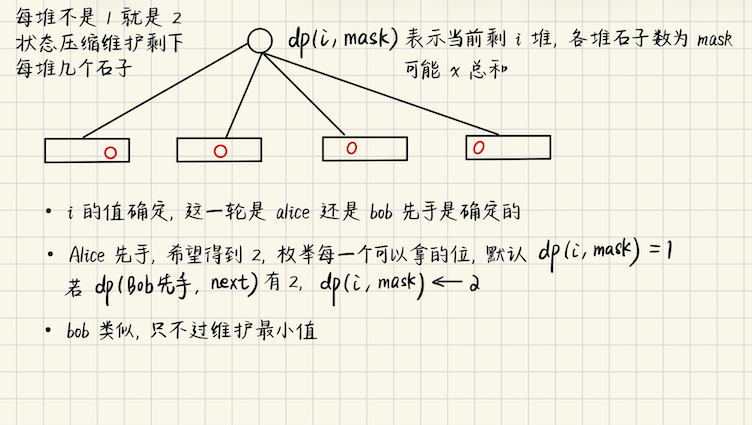 ## 2026“钉耙编程”中国大学生算法设计春季联赛 7 ### 1011 **[01](https://acm.hdu.edu.cn/contest/problem?cid=1203&pid=1011)** 给定一个`01`串,长度为`n`,给定`k`,每次操作$$i$$,可以将$$i, (i + k) \bmod n$$ 都执行$$x \to x \oplus 1$$,问能否通过若干次操作使得原串成为回文串 **算法分析** > 结论,一个环,每次走$$k$$步,最终实际上还是会回到初始位置 构成一个连通块,连通块中的点相互可达,连通块大小是$$n/\text{gcd}(n, k)$$ 假设走的距离是$$d$$,那么回到初始位置,说明$$d$$是$$n$$的倍数 同时$$d$$也必须是$$k$$的倍数,所以总距离$$D = \text{lcm}(n, k)$$ 另外,每次跳$$k$$的单位距离,实际上跳了$$\dfrac{\text{lcm}(n, k)}{k} = \dfrac{n}{\text{gcd}(n, k)}$$步 也就是说,一个连通块的大小是$$n / gcd$$,一共有$$gcd$$个**不相交的连通块** > 结论,$$i \to (i + \bmod k) \bmod n$$ 那么,$$i$$可达点满足$$\\{i + dk + jn \mid d, j \in \mathbb{N} \\}$$ 令$$g = \text{gcd}(k, n)$$,所有可达点可以写成$$\\{i + dg \mid d \in \mathbb{N} \\}$$ > 观察一,每一次的操作,只能在**同一个连通块里操作**,不能跨连通块 观察二,$$x \oplus 1, y \oplus 1 \Rightarrow x \oplus y \oplus 1 \oplus 1 = x\oplus y$$ 也就是说,`1`次操作并不会改变`1 个数的奇偶性(或者说异或和)` 基于上面的观察,可以推出一个很重要的性质 **同一个连通块压缩成一个序列**,在这样的序列中,只要`1`的奇偶性和初始时候相同 那么一定可以构造出来 1)如果`1`个数是偶数,可以构造出全`0`串(一定回文) 2)如果`1`个数是奇数,那么可以构造出**只有一个`1`的串**,并且这个`1`可以放在任意位置 > 全`0`怎么构造? 如果相邻的是`11`,那么很简单,直接`(i, i+k)`操作 如果相邻的是`10`,那么`(i, i+k)`,然后`(i+k, i+2k)`,此时`i+k`作为“跳板”,值仍然是`0`没有变化 想到这里就可以做了 对于每个下标位置$$i$$,得到它所在的连通块$$bel_i = i \bmod gcd$$ 那么$$\\{i, i+g, i+2g, \cdots, i+kg\\}$$都在一个连通块里,连通块的编号是$$i$$ 对称的位置$$\\{n-1-i, n-1-i-g, \cdots \\}$$也会在一个连通块中 连通块的编号是$$(n - 1 - i) \bmod g = g - 1 - i$$ (是因为$$g = gcd(n, k), n \bmod g = 0$$) 对每一个$$(i, j)$$回文对称的位置,找到他们所属的连通块编号$$(bel_i, bel_j)$$ 然后缓存下来,作为一对`pair` > 检查每一对连通块 pair `(u, v)` 1)如果$$u \neq v$$并且他们的异或和也不等,那么是没法满足的 否则就可以(构造的话,异或和是偶数变成全`0`,是奇数,找对称的位置放`1`就可以) 2)如果$$u = v$$,它们在一个连通块中,一个连通块中`1`的个数奇偶性是确定的 如果有奇数个`1`,必须满足**奇回文串**,并且`1`要在正中间,其他位置都是`0` 如果有奇数个`1`但是$$n \bmod 2 = 0$$的话,就不合法,否则就合法 ### 1005 **[Rain](https://acm.hdu.edu.cn/contest/problem?cid=1203&pid=1005)** 给定`n`个储蓄罐,编号$$1 \sim n$$,初始时候第`i`个储蓄罐有$$a_i$$的雨水 在第`0`天可以将两辆车放在任意两个储蓄罐面前 接下来`k`天,按顺序发生如下事件 1)每个储蓄罐都会增加`1`单位雨水 2)两辆收集车分别收集当前储蓄罐的全部雨水,如果两辆车位置重合,那么雨水只会被收集一次 3)每一辆车可以移动,或者不移动,要移动就$$i \to i+1$$或者$$i \to i-1$$ 现在问,最多可以收集多少单位的雨水 **算法分析** 考虑$$i$$这个位置被收集了多少次,假设收集时间是$$\\{t_1, t_2, \cdots, t_m\\}$$ 不难发现,和**中间收集过程**无关,中间收集的时间,只是把一段连续的数分成若干段 **总的收集量**是不变的,只和**最后一次收集的时间**$$t_i$$有关 那么$$i$$位置能贡献的收集量,实际上就是$$V_i = a_i + t_i$$ > 贪心 贪心地发现,最优策略,考虑枚举两辆车的分割点,分成一段前缀和一段后缀 以前缀为例,要想收集到尽量多的雨水,一定是在这段前缀中**“往返跑”** 只需要关注最后一次跑了的距离,会有一些雨水收集不到 假设从$$l \to r$$,那么收集不到的雨水数量分别是$$\\{len-1, len-2, \cdots, 2, 1, 0\\}$$ 其中$$len$$表示区间长度 从而$$[l, r]$$区间在$$k$$段时间内能收集到雨水的数量就是**确定的** 总雨水量是$$tot = \sum\_{i = l}^{r} a_i + k\cdot len$$,收集不到的数量是等差数列的求和 那么能收集到的雨水数量$$\displaystyle H(l, r) = \left( \sum\_{i = l}^{r} a_i \right) + k\cdot len - \dfrac{len(len - 1)}{2}$$ 预处理,枚举**往返跑**的终点$$r$$,往返跑单段路程是$$[\max(1, r - k), r]$$ 代入上述$$H(l, r)$$求出这段路程的收益$$H_r$$,然后$$dp_1(i)$$维护$$H$$数组的前缀最大值 同时$$dp_2$$维护后缀最大值,枚举分割点,$$dp_1(i) + dp_2(i+1)$$就是答案 ### 1001 **[card](https://acm.hdu.edu.cn/contest/problem?cid=1203&pid=1001)** 给定`n`个点`m`条边的无向图,每条边有个权值,表示通过这条边的时间 你在第$$i$$个点,可以喝下魔力效果为$$a_i$$的药水,每喝下一瓶药水 可以任意使得自己的魔力值$$+a_i$$或者是$$-a_i$$,可以是负数,在一个点你可以喝下任意多瓶药水 目标是使得自己的魔力值恰好为$$V$$,问达到目标的最少时间 **算法分析** ```math k_1a_1 + k_2a_2 + \cdots + k_ma_m = V \\ k_1a_1 + k_2a_2 + \cdots + k_ma_m = \text{gcd}(a_1, a_2, \cdots, a_m) ``` 当且仅当$$\text{gcd} \mid V$$才能达成目标 拆点,枚举$$V$$所有约数$$d$$,$$(u, d)$$,转移就是$$(v, \text{gcd}(d, a_i))$$ 用 dijkstra 求解 ### 1003 **[Livehouse](https://acm.hdu.edu.cn/contest/problem?cid=1203&pid=1003)** 举办演唱会,用区间$$[l, r]$$表示一场演唱会,演唱会没有**相互包含的区间** 但可能有相交,对于不相交的两场演唱会,可以交给同一个乐队负责 对于相交的呢?一个乐队只能负责其中的一场,换句话说,同一支乐队负责的演唱会,不能相交 现在给定$$K$$,要求安排的乐队数$$\leqslant K$$的条件下,能有多少个演唱会区间 (形式化地说,不包含相同元素、且两两没有包含关系的非空时间段集合) **算法分析** 如果看作**括号匹配**问题呢?演唱会开始记为左括号,结束记为右括号 1)因为区间没有包含关系,所以`)`匹配的是最左端的左括号,(按队列匹配) 2)能过安排的乐队数$$\leqslant K$$,能不能看作**背包的容量是**$$K$$ 考虑 dp,对每个位置,决策放`+1`还是放`-1` 1)如果是`+1`,说明乐队区间有重合,对乐队的需求`+1`(即背包扩容) 2)但要注意的是,如果`-1`,实际上是之前的某个乐队可以解放出来 怎么办呢?实际上,我们只需要关注**前缀和的最大值**,即`+1`最大扩容到哪里 前缀和记为`S`,如果解放了一个乐队,那么`S -= 1`,之后如果有需求乐队,`S += 1` 那么扩容的过程,$$v \to \max(S+1, V)$$,$$V$$表示背包之前扩容扩到的最大值 那么转移如下,枚举上一个位置的前缀和$$S$$,背包扩容体积$$V$$ 对于$$i$$位置,$$S < i, \quad S \leqslant V \leqslant n$$ (每个位置,所需要的乐队数量,**至少是当前的前缀和**,括号匹配嘛,就看栈中还有多少个左括号残留) 1)如果放`+1`,那么$$nV = \max(S+1, V)$$,$$dp(S, V) \to dp(S+1, nV)$$ 2)如果放`-1`,那么解放了之前的一个乐队,所需要的最大容积不变$$dp(S, V) \to dp(S - 1, V)$$ 3)还有`2`种情况容易遗漏,什么都不放,$$ndp = dp$$ 4)放了`+1`同时放了`-1`,这个时候需要对乐队进行**扩容** 有$$nV = \max(V, S+1), dp(S, V) \to dp(S, nV)$$ ### 1010 **[Shift](https://acm.hdu.edu.cn/contest/problem?cid=1203&pid=1010)** 给定$$n \times m$$的表格,每一行有一个字符串,第$$i$$个字符串占据$$[p_i, p_i + |S| - 1]$$ 维护`q`次操作,每次操作分为以下两种 ```bash 1 x d,将 x 行的字符向左 (d < 0) 或者向右 (d > 0) 移动 |d| 个单位 2 x,找出能够和第 x 行完全对齐的,并且由相同字符构成的最长连续子串的长度 ``` 这里$$m \leqslant 20$$,对于每个查询,暴力枚举$$(i, len)$$,然后看一下`tar = target[i...i+len-1]` 问题是,要`for`所有的$$y \in$$`其他行`,复杂度肯定爆炸 **算法优化** 注意到$$m \leqslant 20$$,那么所有可能的子串组合$$(i, len)$$也非常小 可以对每一行**预处理**,假设对于$$S_y$$表示第`y`行的字符串 > 但注意,我们只需要求出最长的可能的匹配子串的长度,不需要知道具体是谁 **预处理**的时候,就暴力所有可能的子串$$(i, len)$$,并且计算`hash`值 这样可以用`cnt(i, len, hash) ++`来维护 查询的时候,对于`x`,枚举`x`的所有子串$$(i, len)$$,只要`cnt(i, len, hash) > 1` 那么`len`可以用来更新答案 > 修改呢? 修改更简单了,因为不会改变`hash`值,`cnt(i, len, hash)`只会改变起始坐标 `cnt(i, len, hash)--, cnt(新坐标, len, hash)++`就可以了 ### 1009 **[Sand](https://acm.hdu.edu.cn/contest/problem?cid=1203&pid=1009)** 有一个长度为`n`的序列`a`,一开始都是`0` 给定一个长度为$$m$$的操作序列,$$(r_i, v_i)$$,每个操作$$a[1, r_i]$$和$$v_i$$取`max` 给定`q`次询问,依次执行$$[L_i, R_i]$$里面的操作之后,`a`的和 特别地,设$$p_i$$是左边第一个$$v_j > v_i$$的位置,那么 ```math \max_{j = p_i + 1}^{i} r_j = r_i ``` **算法分析** > 先对题目的描述重新整理一下 对于某个位置$$v_i$$,记一下左边第一个大于它的元素位置$$j = p_i$$ 那么$$v\_{p\_i} > v\_i$$,换句话说,$$\\{p\_i+1, p\_i+2, \cdots i \\}$$这几个位置的操作 引入的值都$$\leqslant v\_i$$ 也就是说,`i`位置执行了$$v\_{i}$$这个操作之后,**所有针对**$$\\{ p\_i+1, p\_i+2, \cdots, i\\}$$这些位置的操作都是**无效的** 因为$$v_i$$会覆盖那些位置,真正能够影响到$$i$$的值的(有贡献的) 只有`{ i, p[i], p[p[i]], .... }`,其中$$p_i$$是左边第一个$$> v_i$$的位置 > 暴力想法 注意到几个性质 1)考虑**大根单调栈树**,令$$p_i \to i$$连边,这样一个节点$$x$$就是它子树的最大值 同时,子树也对应原序列**连续的一段** 2)有效操作序列,我们根据之前的分析`i -> p[i] -> p[p[i]] ....`,恰好对应**大根单调栈树**往上爬的过程 可以**树上倍增**,找出$$[L, R]$$的最靠近`L`的祖先 从祖先节点到子节点,`v`是严格单调递减的,那么对于每个$$v$$,它会管理哪些区域呢? 3)对于$$v_i$$,它管理哪些区域呢?假设说上一个管辖的范围是$$[1\cdots last]$$ 那么引入一个新的$$(r_i, v_i)$$,只有$$r_i > last$$,此时$$[last+1, r_i]$$才会被$$v_i$$管辖 而`last`之前的不归$$v_i$$管(因为最大值不是它!)于是$$v_i$$的贡献是$$v_i \cdot (r_i - last)$$ 然后$$last \to r_i$$,这样就得到了一个$$O(m \times q)$$的暴力做法 > Segtree Beats 还是回到线段树的问题,**怎么合并左右两个子区间** 对于树链剖分出来的若干段区间$$[l, r]$$,$$l \to r$$是从根节点依次去往子节点 根据上面的分析$$L: [l, mid], \quad R: [mid+1, r]$$ 可以知道的是,$$L$$区间中操作的$$v$$**一定大于**$$R.v$$,即$$L.v \geqslant R.v$$ 于是我们关心$$L, R$$分别会对$$[l\cdots r]$$贡献多少?观察两个区间的`maxr`,即$$(v, r)$$操作中**最靠右的`r`** **本题的性质** 因为$$v$$单调递减,维护`maxr`,后面的`v`较小,**只对超出`maxr`的部分有贡献** 贡献值是$$v \cdot (r - maxr)$$ 1)如果`L.maxr`非常大,大到覆盖掉右边,即`L.maxr >= R.maxr`,那么右半边的贡献为`0` 合并后的总的贡献完全取决于左区间`L.res` 2)否则,`L.res`的贡献仍然会有,但是只能起作用到`[l...L.maxr]`,剩下的由`R`中的操作来负责 此时`R.maxr > L.maxr`,也就是说**`R`子树中存在一个操作**,它的`r > L.maxr` 想办法二分找到这个操作编号`p`(对应在`R`中的叶子节点) > Segtree beats 算法流程 **算法思想** 维护一个`line`,`line`会切分前缀,`<= line`的部分无贡献,`> line`的部分才会产生贡献 这个切分位置,可以线段树二分找到 如果线段树一整个区间都`> line`,查询,区间合并的时候,考虑**不去递归它**,而是在预处理的时候,先**缓存下来** 合并区间的时候,用缓存的值 1)预处理,算出**左边的`maxr`都不会切到右子树**,此时右子树的贡献多少? 缓存下来,`cache(p) = calc(右儿子不受左边 maxr 影响,产生的贡献)` 这样,缓存就算出了右区间整段都有贡献时候的情况,之后不必递归,而是直接用缓存的值`cache(p)` 2)查询,具体实现的时候,针对一段前缀,维护`baseline`从`0`开始 一开始`baseline = 0`,做完之后,更新`baseline = t[p].maxr` 3)贡献计算 3.1) 若`baseline >= 整个区间的 maxr`,整个区间贡献是`0` 3.2) 若左区间的`maxr`都超过`baseline`了,那么右区间整个都有贡献,`+cache(p)` 左区间呢?左区间可能还会贡献一段后缀,递归左区间,`递归左区间 + cache(p)` (其中`p`表示当前线段树的节点编号) 3.3) 否则,切割点在右区间内,直接递归右区间 **算法实现** 1)根据上面的讨论,对于操作$$[l_i, r_i]$$,我们让$$t = r_i$$,那么沿着$$t$$**树上倍增**往上找 找到第一个$$\geqslant l_i$$的点$$s$$,**树链**$$s \to t$$就是我们要考虑的 2)对于`树链 s -> t`,剖链,注意,树链剖分 + 线段树,线段树的叶子节点**必须是`dfs 序`** 即`leaf[ dfn[i] ] = a[i]`(线段树只是打辅助,`[li, ri]`对应的是`dfs 序`区间) 3)自顶向下,对`log`段重链,线段树查询 > 算法实现 ```bash void solve(int cas) { int n, m, q; cin >> n >> m >> q; vector<S> op(m+1, S{}); // (cache, v, maxr) for (int i = 1; i <= m; i++) { i64 ri, vi; cin >> ri >> vi; op[i] = S{0, vi, ri}; } vector<vector<int> > g(m+1); vector<int> stk; vector<int> p(m+1, 0); for (int i = 1; i <= m; i++) { auto [_, vi, ri] = op[i]; while (stk.size() and op[stk.back()].v <= vi) stk.pop_back(); if (stk.size()) p[i] = stk.back(); stk.push_back(i); } for (int x = 1; x <= m; x++) { auto fa = p[x]; g[fa].emplace_back(x), g[x].emplace_back(fa); } HLD hld(0, g); hld.updgo(m); vector<S> dfn(m+5, S{}); for (int i = 1; i <= m; i++) { dfn[ hld.l[i] ] = op[i]; } SkylineSegtree<S, i64> tr(dfn, m+1); i64 ans = 0; for (int i = 0; i < q; i++) { i64 li, ri; cin >> li >> ri; i64 line = 0; i64 t = ri, s = hld.getanc(t, li); auto seg = hld.path(s, t); reverse(seg.begin(), seg.end()); i64 res = 0; for (auto [lj, rj] : seg) { res += tr.query(lj, rj, line); } ans ^= res; } cout << ans << "\n"; } ```
0
0
上一篇:2026年四月算法竞赛选题(一)
下一篇:2026年五月算法竞赛选题(二)
看完文章有啥想法
发布评论
281 人参与,0 条评论